


酷睿Ultra独家解析:别家不敢说的东西,全在这了
前言:酷睿Ultra来了,但目前的解析着实有些无聊
最近几天,关于英特尔第一代酷睿Ultra(并非14代酷睿)的架构解析内容开始多了起来。
一方面,这是因为英特尔在9月19刚刚召开了他们今年的“架构日”活动,并公布了了Intel 4制程、Foveros封装、Meteor Lake架构的很多信息。

另一方面,此前在今年8月份,英特尔方面曾邀请了一些媒体去参观了他们的封测工厂、实验室,并分享了部分新品的信息,而这些信息近日也正式解禁。
正因如此,现在可以看到有许多内容都在讨论英特尔新款处理器的种种细节,并分析它的制程、半导体材料、封装技术的原理,以及所谓“一分四”的设计等等。

但纵观这些内容大家可能会发现一个现象,它们虽然看似讲了很多很细节的东西,但多半都只是“看图说话”,照着官方PPT做解说,并没有太多自己的看法或对比分析。因此也就导致这些关于“酷睿Ultra”的解析内容,有些过于相似。
为什么会这样?一方面,当然是因为目前英特尔的新架构从严格意义上来说,还没有真正地发布、上市,所以哪怕有些已经拿到了产品、知道了更详细的参数,也不能说出来。另一方面,英特尔此次“架构日”上公布的产品资料,本质还是过于偏技术向。如果只是照着这些PPT去写,确实很难让普通消费者感兴趣。

不过以上这些对于我们三易生活来说其实都不是问题,因为我们通过相关渠道,得知了一些更详细的产品资料。而且大家只要看过以往的相关内容就会知道,我们对于英特尔下代架构的关注、分析准备,也不是一天两天的事情了。所以在看到这一轮的“分析内容”后我们意识到,是时候来写一些其他人所不知道、或是不能写的东西了。
首先,我们来详细聊聊所谓的“一分四”
其实早在几年前,我们就曾在相关内容中指出,英特尔是整个消费电子行业里对“制程数字”态度最诚恳、最不“吹牛”的厂商。
但这种“诚恳”却带来了两个问题,其一是英特尔从来不会宣传制程上的“小改款”,比如大家都知道,从第5代到第11代酷睿的桌面版,英特尔方面一直声称他们用的是14nm制程。但实际上,这个“14nm”本身的工艺细节是一直有在改进的,其晶体管密度、处理器所能达到的频率等等实上也都在提升,而且提升幅度并不小。但英特尔自己不宣传,就反而造成了部分消费者的误解,以为他们的制程一直都没有进步。

其次,就是按照英特尔以往的做法,他们的处理器指的是整个核心“统一”制程的思路。也就是本身需要高频、需要高密度的计算部分,与其实并不需要高频、高密度的IO、核显、缓存等部分,都是从一块晶圆上切出来的。
很显然这就带来了很大的浪费,也提高了制造成本,还不利于宣传。看看隔壁的AMD,早在初代锐龙上就已经实现了计算核心和IO核心的分制程制造,只把计算部分用先进制程,宣传时也不提及IO部分的制程。
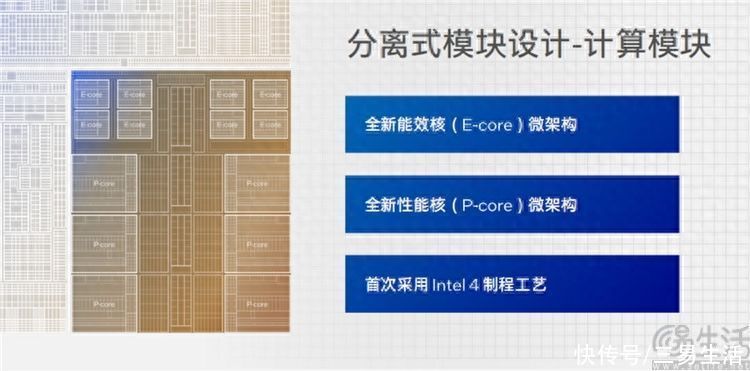
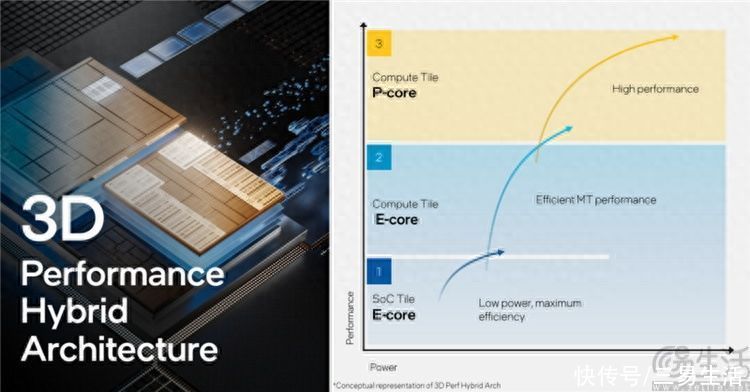
或许是因为明白了这一点,所以在第一代酷睿Ultra、或者说Meteor Lake架构上,英特尔总算是搞出了他们的模块化设计。其中只有CPU核心(性能P核+能效E核)部分使用英特尔自家的“Intel 4”制程打造,而ARC核显、SoC核心、IO控制器等部件,则都会采用5nm、7nm等更低成本的工艺、甚至包括外包(台积电)生产,以降低成本、提高良品率。

但是与竞争对手仅仅将不同功能模块单纯焊接在同一个PCB上,靠PCB内部的铜电路进行通讯的做法相比,英特尔在模块之间的互联方式上要想得更“细”一点。是字面意思上的“细”,因为Metor Lake模块之间采用了硅晶片直接堆叠的方式,来实现电气互联。
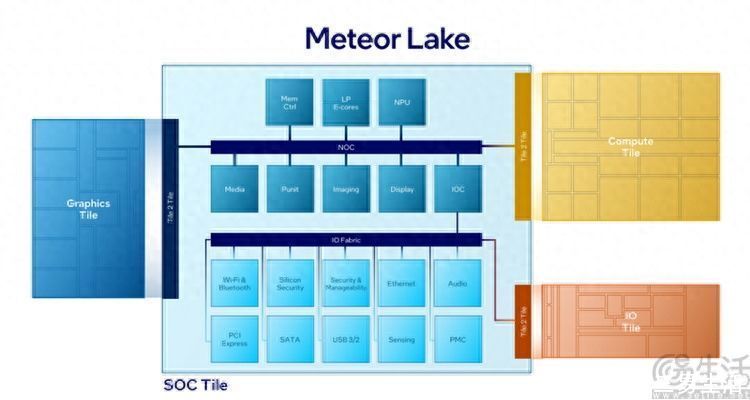
这样做的好处是什么?很简单,模块之间的互联路径短了,延迟就降低了、带宽也大大增加了。于是,它也就解决了模块化CPU设计往常可能会出现的一些“大问题”。
不退步的内存控制器,这本身其实就是进步
在第一代酷睿Ultra之前,英特尔CPU内部的计算模组(CPU核心)和内存控制器、缓存、核显,都是基于相同的制程、在一整块晶圆上刻出来的。而现在换了新架构之后,不同的模组现在变成了用不同的晶圆“粘”在一起了。
那么这会造成什么问题?没错,从理论上来说,这会导致计算模块和其他模块之间互联线路的电气性能退步,从而可能反而造成CPU内存频率下降、缓存延迟增大等问题。
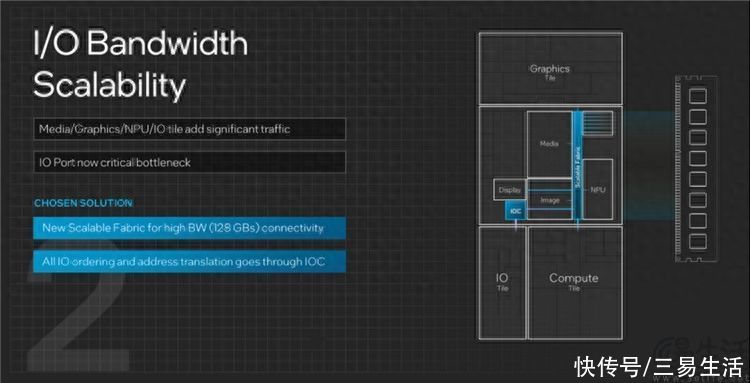
有没有觉得很眼熟?没错,这些现象前几年我们在隔壁家的处理器上其实就已经见到过了。但是英特尔这次真正厉害的地方,就在于他们成功规避了这些原本可能发生的退步现象。
从我们三易生活拿到的独家资料来看,移动版第一代酷睿Ultra处理器支持至少四种内存频率,分别是DDR5 1R 5600MHz、DDR5 2R 4400MHz,LPDDR5 6400MHz,以及LPDDR5X 7467MHz。

与目前的13代酷睿移动版相比,移动版第一代酷睿Ultra的内存兼容频率,在所有类型的内存上都没有降低,这就证明英特尔成功解决了模块化CPU可能面临的内部通信壁垒问题。或者也可以反过来理解为,他们选择一直等到解决了这些问题、确保新的模块化CPU设计不会导致部分性能参数下降为止,才切换到了这一新设计上。而这种“不让用户为新技术短板买单”的态度,显然是值得点赞的。
频率低了、缓存大了,我们的“梦想”也得以实现
就在不久前我们三易生活还曾感叹,最近几年的CPU设计大有重新走上“高频路线”,以发热和功耗强行换取性能增长的危险。但是在第一代酷睿Ultra上,情况很可能发生了良性的转变。
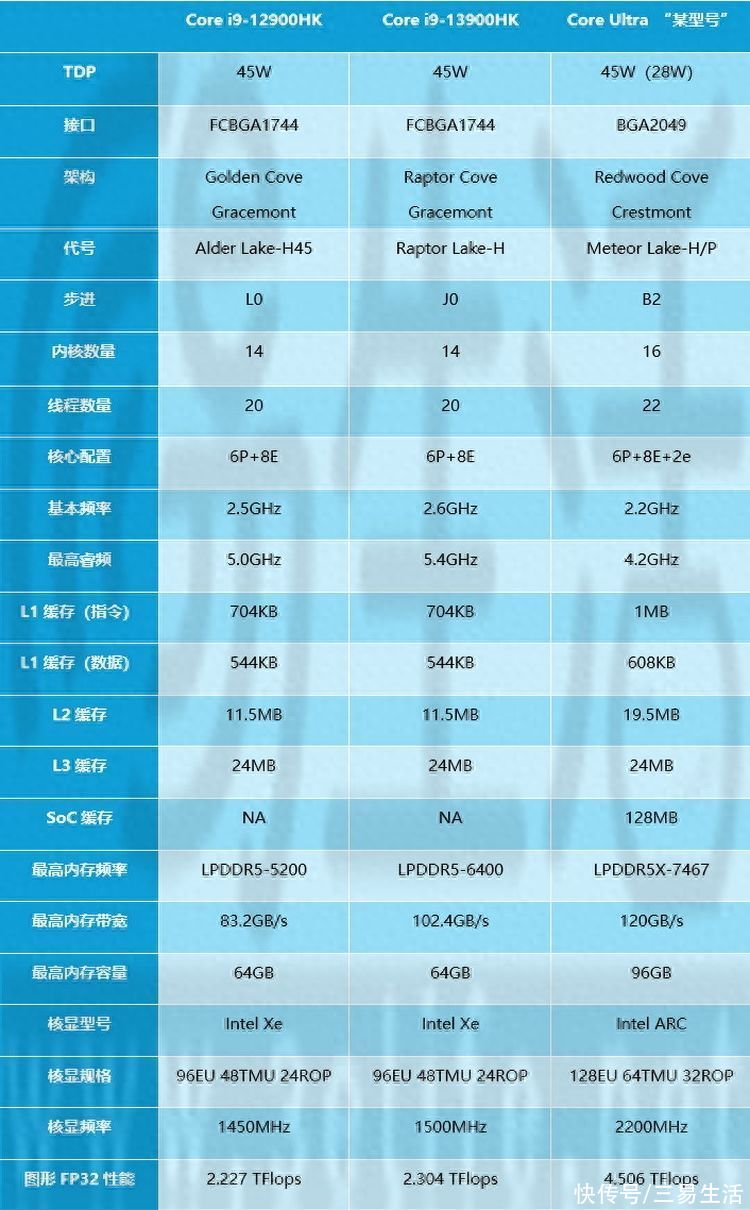
我们三易生活结合目前各方的消息源,整理出了上面这张表格。从中可以看到,与12代、13代的移动版45W酷睿相比,新的酷睿Ultra似乎主频有着比较明显的降低,同时将L1缓存和L2缓存进行了增大,并新增了位于SoC模块里的128MB系统缓存。
很显然,这“恰好”符合了我们此前对于CPU发展还是应该追求IPC、大缓存、高并发,而非高主频方向的期望。不过值得注意的是,目前的频率相关数据还不能代表最终上市的状态,但基本可以确定的是,最终上市的版本主频依然要低于13代酷睿。也就是说,新架构这一次至少在“破除频率迷信”这个维度,走出了正确的一步路。
当然,熟悉英特尔以往产品线发展规律的朋友可能马上就会想到,既然这一代的酷睿Ultra频率降低了,那么有没有一种可能,英特尔在下代产品上“吃透”新制程和新架构后,会推出大幅提升频率的“半代升级”型号呢?
别说,确实有这种可能。但从目前已知的信息来看,英特尔似乎还是更急于在短期内完成制程和架构的多代跨越。所以即便Meteor Lake将来也有“Refresh”,我们推测其产品规模可能也并不大,或许只会限定在少数细分产品线上。
最后关于新的内置NPU设计,我们有点想法
想必大家都已经知道了,英特尔这一次为Meteor Lake架构集成了NPU单元,使得其具备了独立的低功耗AI加速能力。

请注意,这里面有两点是需要特别强调的。第一是这并非英特尔的第一款NPU设计,因为他们早在多年前就已经有NPU产品了,只不过是第一次集成到消费级CPU里而已。

Meteor Lake的集成NPU,和这玩意或多或少有些联系
其次,实际上从10代酷睿-X开始,英特尔就已经为旗下CPU本身添加了AI、深度学习相关的加速指令集,而且在Xe、ARC架构的GPU里,也都具备AI加速的相关单元。

从目前的官方资料来看,Meteor Lake支持异构AI计算、并不只依赖NPU
所以这就让我们产生了一些大胆的想法,一是Meteor Lake、或者说“第一代酷睿Ultra”的AI加速功能,到底是只依赖于新集成的NPU,还是可以实现CPU、GPU、NPU,甚至外置独立显卡的“异构加速计算”?
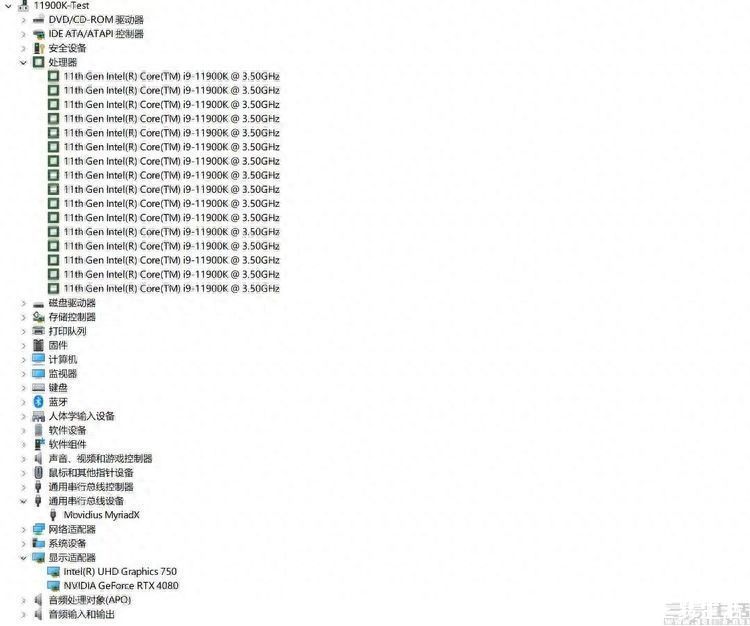
我们的测试平台,早已准备多时
第二就是从此前泄露的一些信息来看,Meteor Lake的NPU会得到微软Windows系统的原生支持,甚至可以直接在任务管理器里看到NPU的占用率。这就不禁令我们感到好奇,如果使用一块内置DLBoost指令集的英特尔老款CPU、搭配ARC独显,再插上英特尔的外置NPU计算棒,这套组合是否也能在届时的新版Windows系统、新版驱动下,享受到“AI加速”的好处呢?
说实在的,针对这个问题,我们三易生活已经准备了很久,或许不久后就能得到一些有趣的答案。我们相信,如果英特尔允许带有DLBoost的老款CPU+ARC独显+NPU计算棒的组合也能受益于新驱动的加成,那么对于现有的用户来说,或许将会有助于巩固他们的用户粘性。
【本文部分图片来自网络】







